
Azure SQL Managed Instance and in-database machine learning
- Mattia Cavallotti
- 27 nov 2021
- Tempo di lettura: 7 min

Aggiornamento: 5 nov 2022
In this demo we will show you how to create, train and deploy a machine learning model directly in an Azure SQL Managed Instance relational database.
Azure SQL Managed instance is the service that combines almost total compatibility with the SQL Server engine with the benefits of a PaaS platform, isolated in a native virtual network with its own private IP.
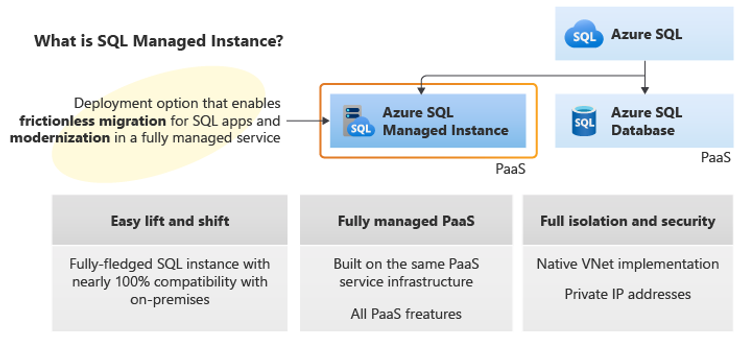
Machine Learning Services is one of the capabilities of Azure SQL Managed Instance.This service offers machine learning directly in-database with the ability to execute Python and R scripts for predictive analysis within SQL stored procedures.
You can use scripts to clean and transform data, train a model and deploy it directly into the database..
No need to move your data between different environments and eliminating the security and compliance issues resulting from these movements.
The model will be called up through T-SQL procedures to make predictions on the new data.
In this demo we will use a Data Science Virtual Machine as a workstation and jumpbox to the Managed Instance.
To connect to the SQL Managed Instance from tools such as SSMS or Azure Data Studio, the machine from which you are connecting must be:
in the same virtual network as the Managed Instance;
or in a different virtual network but linked via peering to the virtual network of the Managed Instance;
or connected to the virtual network of the Managed Instance or to a Hub network through a secure connection to Azure (S2S VPN, P2S VPN, ExpressRoute).
In this scenario the virtual machine is located in the same network as the Managed Instance, but this can vary from the network design that has been set up in your Azure environment.The Data Science Virtual Machine is very useful because it already comes with a series of pre-installed programs and packages for data analytics, data science and AI.
How Python in SQL works
First you need to enable the Machine Learning Service by executing the following T-SQL statement on the Managed Instance.
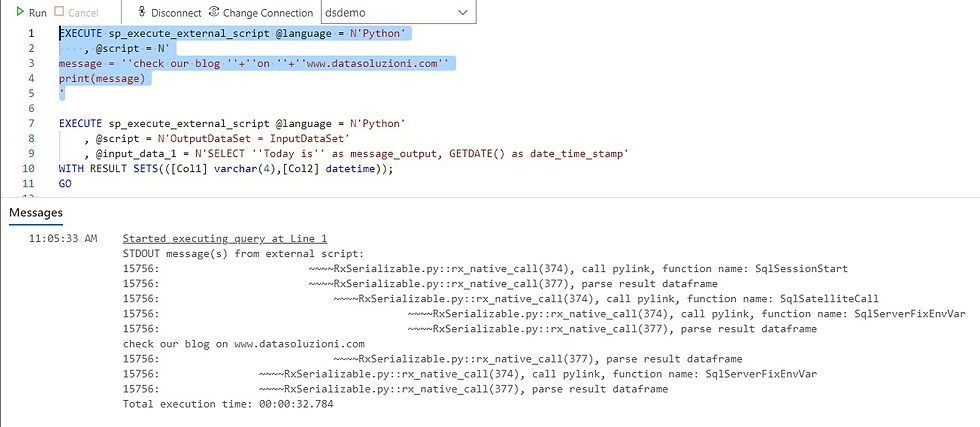
Let's connect to the vm and from SSMS or Azure Data Studio we execute the instruction:
sp_configure 'external scripts enabled', 1; RECONFIGURE WITH OVERRIDE;The execution of the Python code occurs through the system store procedure sp_execute_external_script passing in input the Python script that you want to execute.
Eg:
EXECUTE sp_execute_external_script @language = N'Python'
, @script = N'
message = ''check our blog ''+''on ''+''www.datasoluzioni.com''
print(message)
'
@language: defines the language to call.
@script: defines the commands passed to the Python runtime.
Or:
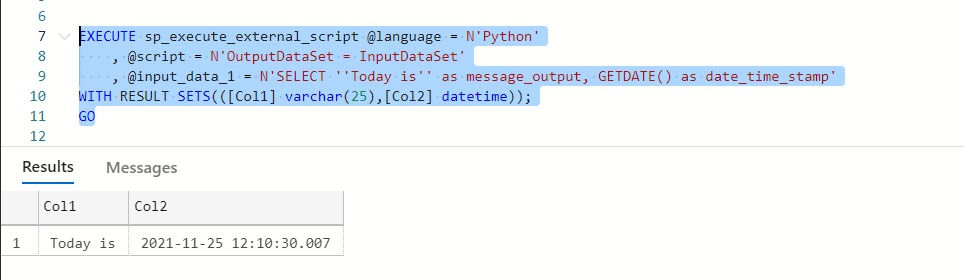
EXECUTE sp_execute_external_script @language = N'Python'
, @script = N'OutputDataSet = InputDataSet'
, @input_data_1 = N'SELECT ''Today is'' as message_output, GETDATE() as date_time_stamp'
WITH RESULT SETS(([Col1] varchar(25),[Col2] datetime));
GOWe can use the predefined variables InputDataSet and OutputDataSet.
The first will input the data from the @ input_data_1 parameter and return the results in the second.
The WITH RESULT SETS clause defines the schema of the data table that will be returned.
Note: By default, sp_execute_external_script accepts a single data set as input, which is usually provided in the form of a valid SQL query, and returns a single Python dataframe as output.
It is possible to generate a dataset or import it directly from the Python script.
EXECUTE sp_execute_external_script @language = N'Python'
, @script = N'
import pandas as pd
s = pd.date_range(''2021-11-20'', ''2021-12-31'', freq=''D'').to_series();
OutputDataSet = pd.DataFrame(s);
'
WITH RESULT SETS(([DateColumn] date));
GO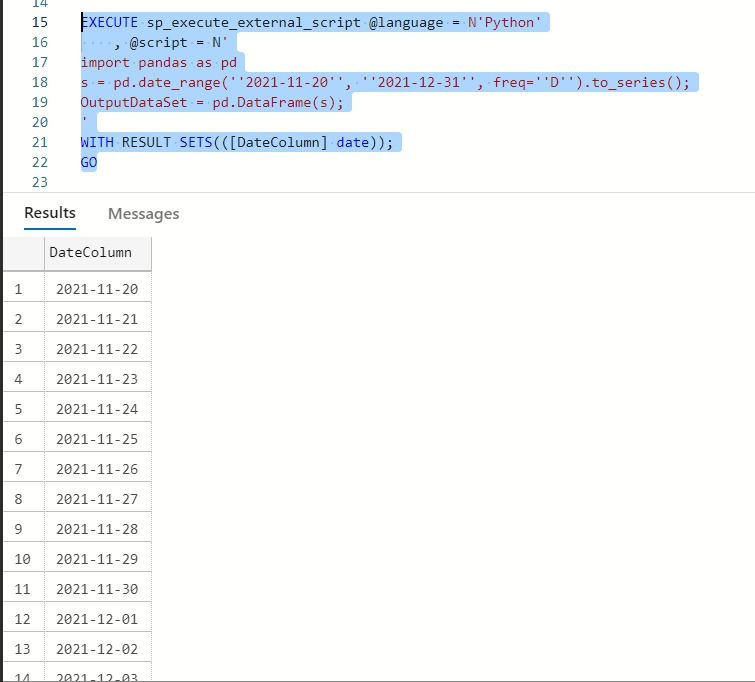
We can introduce data from an existing SQL table, use Python libraries to transform the data, and output the transformed table.
CREATE TABLE tblPython (ID INT Identity NOT NULL,[Value] int NOT NULL)
INSERT INTO tblPython
VALUES (10),(20),(30);
GO
--select * from tblPython
EXECUTE sp_execute_external_script @language = N'Python'
, @script = N'
import numpy as np
import pandas as pd
df=InputDataSet;
df[''ValueSquared'']=np.sqrt(df[''Value''])
OutputDataSet = df;'
, @input_data_1 = N'SELECT * FROM tblPython;'
WITH RESULT SETS(([ID] INT NOT NULL,[Values] INT NOT NULL,[Transofrmation] FLOAT(24) NOT NULL));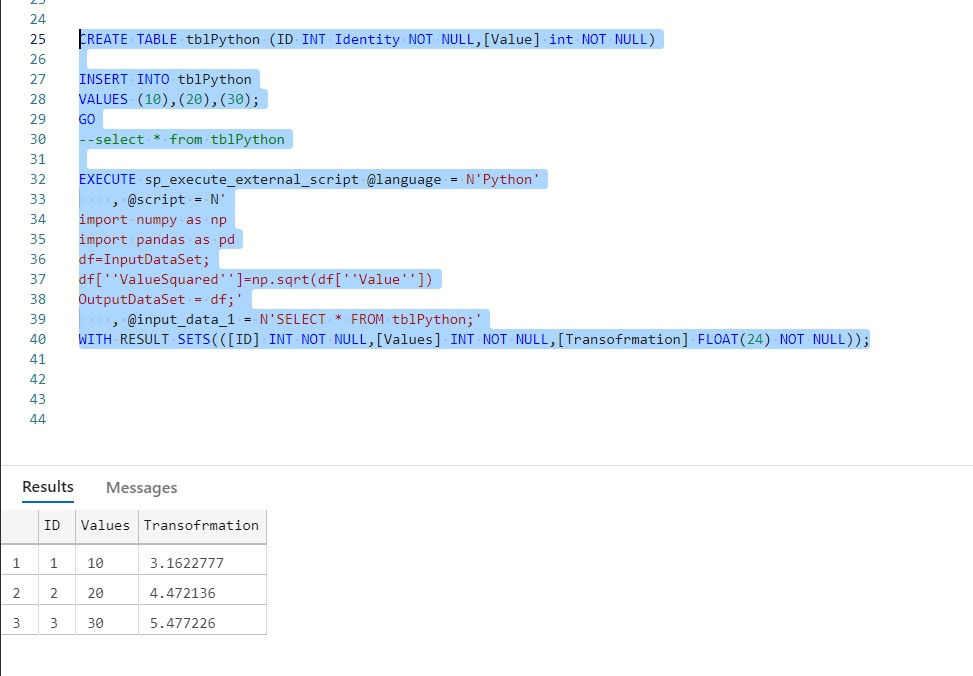
With the same logic we will create two stored procedures.
In the first, a Python script will be inserted in the @script parameter for the creation of a regressive model that will output the trained model.
In the second, another script that will recall the saved model and return the predictions on a new dataset.
Python model
In this section we will import data from an Azure Managed Instance SQL table called tblBoston containing a sample dataset into a Jupyter notebook.
The dataset is the Boston Housing Dataset, derived from information gathered by the United States Census Service regarding housing in the Boston MA area.

The available information is as follows:
CRIM - per capita crime rate by town
ZN - proportion of residential land zoned for lots over 25,000 sq.ft.
INDUS - proportion of non-retail business acres per town.
CHAS - Charles River dummy variable (1 if tract bounds river; 0 otherwise)
NOX - nitric oxides concentration (parts per 10 million)
RM - average number of rooms per dwelling
AGE - proportion of owner-occupied units built prior to 1940
DIS - weighted distances to five Boston employment centres
RAD - index of accessibility to radial highways
TAX - full-value property-tax rate per $10,000
PTRATIO - pupil-teacher ratio by town
B - 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
LSTAT - % lower status of the population
PRICE - Median value of owner-occupied homes in $1000's
On this data we will train the model to try to predict the "PRICE" value.
We open a new notebook in Azure Data Studio and as kernel we select Python 3.
As previously mentioned, a series of tools are already set up in this machine, if you use a different machine you need to install Python and the necessary libraries.
#!pip install azure-identity;
#!pip install azure-keyvault-secrets
#!pip install pyodbc
#!pip install pandas
#!pip install scikit-learn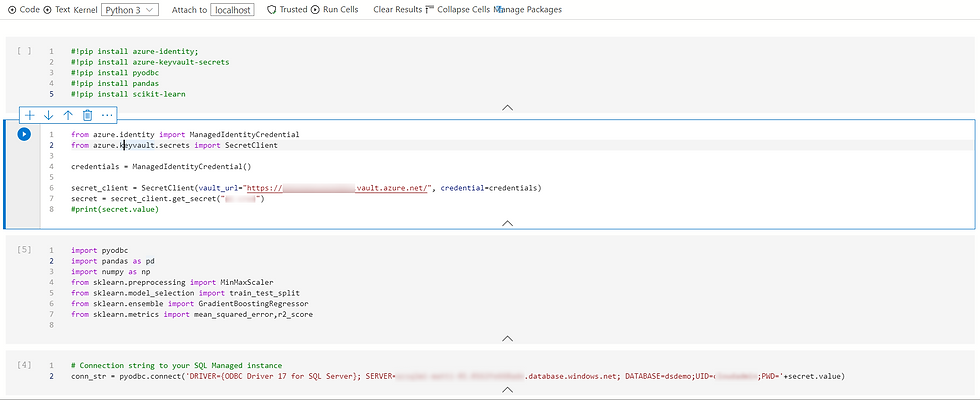
Let's connect securely from the notebook to the SQL Managed Instance to import the data.
In this case, Azure KeyVault was used for secure storage of the login password.
The connection to Azure KeyVault occurs through Managed Identity enabled on the development virtual machine and with permissions to access the secrets in Azure KeyVault.
Although this is a test model it is always a good practice not to explicitly write credentials in connection strings.
from azure.identity import ManagedIdentityCredential
from azure.keyvault.secrets import SecretClient
credentials = ManagedIdentityCredential()
secret_client = SecretClient(vault_url="https://<yourkvname>.vault.azure.net/", credential=credentials)
secret = secret_client.get_secret("<your-secret-for-SQLMI-cred>")
#print(secret.value)We create the dataframe directly from the SQL query on the Managed Instance.
import pyodbc
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error,r2_score
# Connection string to your SQL Managed instance
conn_str = pyodbc.connect('DRIVER={ODBC Driver 17 for SQL Server}; SERVER=<yourmanagedinstanceprefix>.database.windows.net; DATABASE=dsdemo;UID=<your-username>;PWD='+secret.value)
#Retrieve your training data from your SQL table
query_str = 'SELECT * FROM dbo.tblBoston'
df = pd.read_sql(sql=query_str, con=conn_str)
df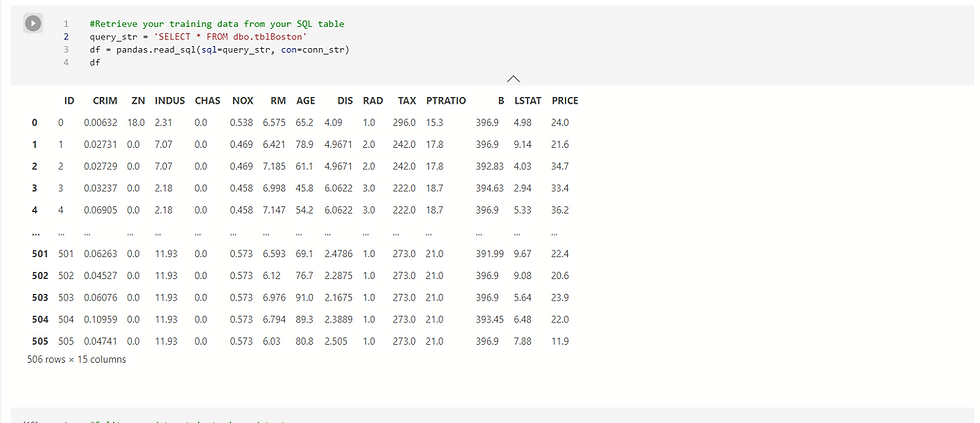
The SQL table is now available as a dataframe.
In this example the data is already clean, but you may need to pre-process or better select features.
Let's train a simple model and see the result.
#Split your dataset in train and test
X_df=df.drop(["ID","PRICE"],axis=1).values
y_df=df["PRICE"].values
X_train,X_test,y_train,y_test=train_test_split(X_df,y_df,test_size=0.3,random_state=0)
#Scale the dataset and train a model
mms=MinMaxScaler()
X_train_scaled=mms.fit_transform(X_train)
X_test_scaled=mms.transform(X_test)
gbr=GradientBoostingRegressor()
gbr.fit(X_train,y_train)
preds = gbr.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, preds))
print("RMSE: %f" % (rmse))
r2=r2_score(y_test, preds)
print("R2: %f" % (r2))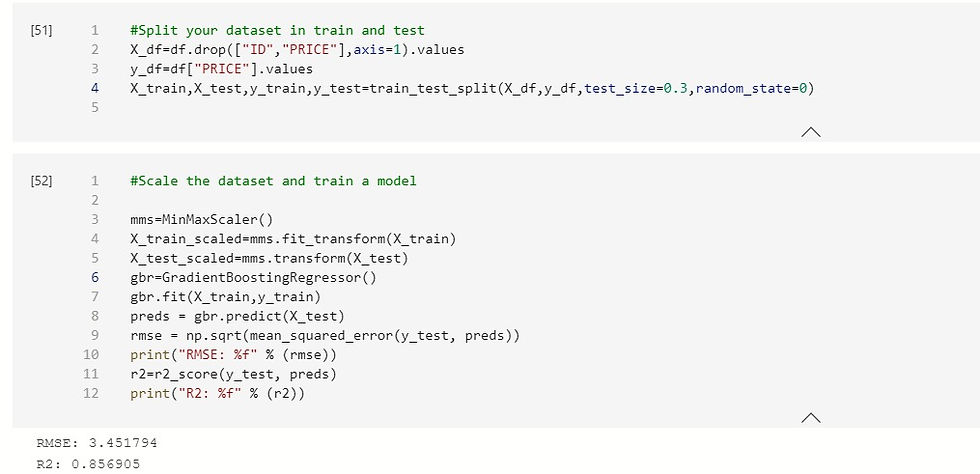
Let's bring the Python model into SQL Managed Instance
At this point we use the sp_execute_external_script system store procedure to insert the model training directly into the SQL Managed Instance database "dsdemo".
Let's open a query editor in Azure Data Studio connected to "dsdemo".
The following SQL script creates a store procedure that embeds the Python model and outputs the model itself as a binary object:
-- Stored procedures that generates and train a Python model
DROP PROCEDURE IF EXISTS generate_boston_model;
go
CREATE PROCEDURE generate_boston_model (@trained_model varbinary(max) OUTPUT)
AS
BEGIN
EXECUTE sp_execute_external_script
@language = N'Python'
, @script = N'
import pickle
import pandas
from sklearn.preprocessing import MinMaxScaler
df=boston_train_input
X_df=df.drop(["ID","PRICE"],axis=1).values
y_df=df["PRICE"].values
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X_df,y_df,test_size=0.3,random_state=0)
mms=MinMaxScaler()
X_train_scaled=mms.fit_transform(X_train)
X_test_scaled=mms.transform(X_test)
from sklearn.ensemble import GradientBoostingRegressor
gbr=GradientBoostingRegressor()
gbr.fit(X_train,y_train)
# Before saving the model to the DB table, convert it to a binary object
trained_model = pickle.dumps(gbr)
'
, @input_data_1 = N'select * from dbo.tblBoston'
, @input_data_1_name = N'boston_train_input'
, @params = N'@trained_model varbinary(max) OUTPUT'
, @trained_model = @trained_model OUTPUT;
END;
GOLet's create the table to host the model and insert it as a binary object from the output of the previous procedure:
-- Create a table to store the model
USE dsdemo;
DROP TABLE IF EXISTS dbo.boston_models;
GO
CREATE TABLE dbo.boston_models (
model_name VARCHAR(30) NOT NULL DEFAULT('default model') PRIMARY KEY,
model VARBINARY(MAX) NOT NULL
);
GO
-- Save the trained model
DECLARE @model VARBINARY(MAX);
EXECUTE generate_boston_model @model OUTPUT;
INSERT INTO boston_models (model_name, model) VALUES('GradientBoostingRegressor', @model);
select * from boston_models
We have now saved the model and can use it for new data predictions.
Let's create the procedure for the predictions
The procedure has as input parameter the model or version we want to use.
In this case we use the one we created previously "GradientBoostingRegressor".
The output of the procedure will be a dataset with the predictions in the "Price_Predicted" field.
In this case @ input_data_1 calls a subset of the same dataset but can be made dynamic, for example, only on new data.
-- Create a procedure for prediction
DROP PROCEDURE IF EXISTS py_predict_houseprice;
GO
CREATE PROCEDURE py_predict_houseprice(@model varchar(100))
AS
BEGIN
DECLARE @py_model varbinary(max) = (select model from boston_models where model_name = @model);
EXECUTE sp_execute_external_script
@language = N'Python',
@script = N'
from sklearn.metrics import mean_squared_error,r2_score
from sklearn.preprocessing import MinMaxScaler
import pickle
import pandas
boston_model = pickle.loads(py_model)
df = boston_score_data
df_score=df.drop(["ID","PRICE"],axis=1).values
target=df["PRICE"]
# Generate the predictions for the new set.
predictions = boston_model.predict(df_score)
# print(predictions)
# Compute error between the test predictions and the actual values.
# pred_mse = mean_squared_error(predictions, target)
# print(pred_mse)
predictions_df = pandas.DataFrame(predictions)
OutputDataSet = pandas.concat([predictions_df, df["PRICE"], df["CRIM"], df["ZN"], df["INDUS"], df["CHAS"], df["NOX"], df["RM"],
df["AGE"], df["DIS"], df["RAD"], df["TAX"], df["PTRATIO"], df["B"], df["LSTAT"]], axis=1)
'
, @input_data_1 = N'Select * from tblBoston where ID > 300'
, @input_data_1_name = N'boston_score_data'
, @params = N'@py_model varbinary(max)'
, @py_model = @py_model
WITH RESULT SETS(("Price_Predicted" float, "Price_Actual" float,"CRIM" float, "ZN" float,"INDUS" float,"CHAS" float,"NOX" float,"RM" float, "AGE" float,"DIS" float, "RAD" float,
"TAX" float, "PTRATIO" float, "B" float, "LSTAT" float));
END;
GOLet's create the table to host the predictions.
--create table to store predictions
DROP TABLE IF EXISTS [dbo].[tblPredictionBoston];
GO
CREATE TABLE [dbo].[tblPredictionBoston](
[Price_Predicted] float(24),
[Price_Actual] float,
[CRIM] float,
[ZN] float,
[INDUS] float,
[CHAS] float,
[NOX] float,
[RM] float,
[AGE] float,
[DIS] float,
[RAD] float,
[TAX] float,
[PTRATIO] float,
[B] float,
[LSTAT] float)
GOFinally, execute the stored procedure py_predict_houseprice, insert the new predictions into the tblPredictionBoston table and display the content.
--Insert the results of the predictions for test set into a table
INSERT INTO tblPredictionBoston
EXEC py_predict_houseprice 'GradientBoostingRegressor';
-- Select contents of the table
SELECT * FROM tblPredictionBoston;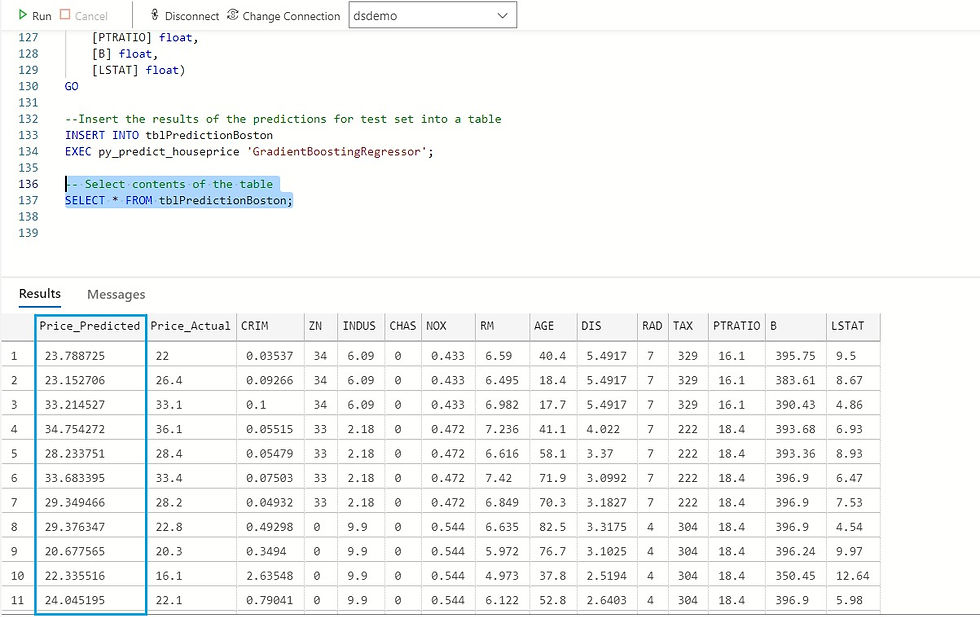
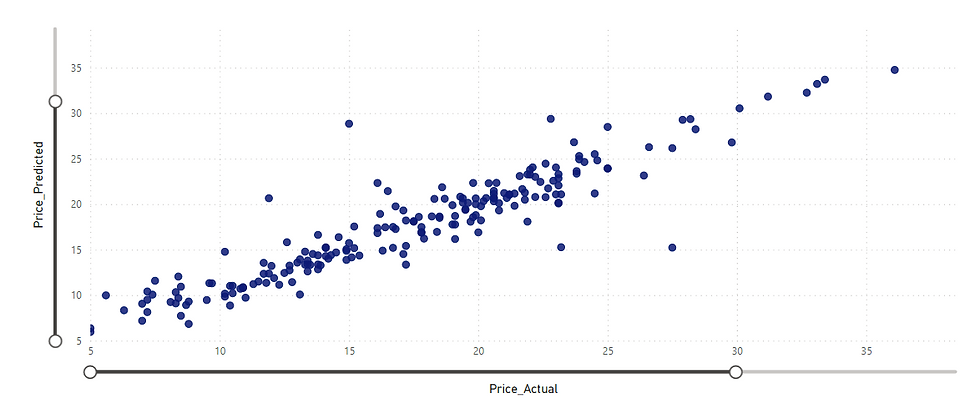
We now have the values predicted by the model available in the "dsdemo" database that we can use, for example, in a Power BI report.
Commenti